Scikit ovat Python-pohjaisia tieteellisiä työkalupaketteja, jotka on rakennettu SciPy, Python-kirjasto tieteelliseen laskentaan. Scikit-learn on avoimen lähdekoodin projekti, joka keskittyy koneoppimiseen: luokittelu, regressio, klusterointi, ulottuvuuden pienentäminen, mallin valinta ja esikäsittely. Se on melko konservatiivinen projekti, joka on melko varovainen välttämään laajuuden hiipimistä ja hyppäämistä käyttämättä todistettuja algoritmeja ylläpidettävyyden ja rajoitettujen kehittäjäresurssien vuoksi. Toisaalta sillä on melko mukava valikoima kiinteitä algoritmeja, ja se käyttää Cythonia (Python-to-C-kääntäjä) toimintoihin, joiden on oltava nopeita, kuten sisäisiin silmukoihin.
Niistä alueista, joita Scikit-learn tekee ei kattavat ovat syvä oppiminen, vahvistaminen, graafiset mallit ja sekvenssin ennustaminen. Se määritellään olevan Pythonissa ja sitä varten, joten sillä ei ole sovellusliittymiä muille kielille. Scikit-learn ei tue PyPyä, joka on nopea ja juuri oikeaan aikaan kokoava Python-toteutus, koska sen riippuvuudet NumPy ja SciPy eivät tue täysin PyPyä.
Scikit-learn ei tue GPU-kiihdytystä useista syistä, jotka liittyvät sen monimutkaisuuteen ja koneiden riippuvuuksiin. Sitten taas, hermoverkkojen lisäksi, Scikit-learnilla ei ole juurikaan tarvetta GPU-kiihdytykseen.
Scikit-Learn-ominaisuudet
Kuten mainitsin, Scikit-learnilla on hyvä valikoima algoritmeja luokitteluun, regressioon, klusterointiin, ulottuvuuden pienentämiseen, mallin valintaan ja esikäsittelyyn. Luokittelualueella, joka koskee objektin luokan tunnistamista ja jota kutsutaan valvotuksi oppimiseksi, se toteuttaa tukivektorikoneita (SVM), lähimpiä naapureita, logistista regressiota, satunnaista metsää, päätöspuita ja niin edelleen. monitasoisen perceptronin (MLP) hermoverkko.
Scikit-learnin MLP-sovellusta ei kuitenkaan nimenomaisesti ole tarkoitettu laajamittaisiin sovelluksiin. Laajojen GPU-pohjaisten toteutusten ja syvällisen oppimisen kannalta katsokaa monia Scikit-learn-hankkeita, jotka sisältävät Python-ystävällisiä syvän hermoverkon kehyksiä, kuten Keras ja Theano.
Regressiota varten, joka on objektille liittyvän jatkuvan arvon määritteleminen (kuten osakkeen hinta), Scikit-learnilla on tukivektorin regressio (SVR), harjanne regressio, Lasso, Elastic Net, pienin kulma regressio (LARS) ), Bayesin regressio, erilaiset vankat regressiot ja niin edelleen. Se on itse asiassa suurempi valikoima regressioalgoritmeja kuin useimmat analyytikot saattavat haluta, mutta jokaiselle mukana olevalle on olemassa hyviä käyttötapoja.
Klusterointiin, valvomattomaan oppimistekniikkaan, jossa samanlaiset objektit ryhmitellään automaattisesti sarjoiksi, Scikit-learnilla on k-keskiarvo, spektriklusterointi, keskiarvosiirto, hierarkkinen klusterointi, DBSCAN ja jotkut muut algoritmit. Jälleen konservatiivisten algoritmien kirjo on sisällytetty.
Ulottuvuuden pienentämisellä tarkoitetaan harkittavien satunnaismuuttujien määrän vähentämistä käyttämällä hajotustekniikoita, kuten pääkomponenttianalyysi (PCA) ja ei-negatiivinen matriisifaktorointi (NMF), tai piirteiden valintatekniikoita. Mallin valinta tarkoittaa parametrien ja mallien vertailua, validointia ja valintaa, ja se käyttää algoritmeja, kuten ruudukkohaku, ristivalidointi ja metriset toiminnot. Molemmille alueille Scikit-learn sisältää kaikki hyvin testatut algoritmit ja menetelmät helposti saatavissa olevissa sovellusliittymissä.
Esikäsittely, johon sisältyy ominaisuuksien poiminta ja normalisointi, on yksi koneoppimisprosessin ensimmäisistä ja tärkeimmistä osista. Normalisointi muuttaa ominaisuudet uusiksi muuttujiksi, joiden keskiarvo ja yksikkövarianssi ovat usein nollia, mutta joskus makuu tietyn vähimmäis- ja enimmäisarvon välillä, usein 0 ja 1. Ominaisuuden poiminta muuttaa tekstin tai kuvat numeroiksi, joita voidaan käyttää koneoppimiseen. Tässä taas Scikit-learn palvelee kaikkia maukkaita klassisia ruokia, joita voit odottaa tässä smorgasbordissa. Voit vapaasti kerätä kumpi tahansa vetoaa sinuun.
Huomaa tämä ominaisuus uuttaminen on aivan erilainen kuin ominaisuus valinta, mainittiin aiemmin kohdassa dimensioiden vähentäminen. Ominaisuuden valinta on tapa parantaa oppimista poistamalla muuttamattomat, kovariaanit tai muuten tilastollisesti merkityksettömät ominaisuudet.
Lyhyesti sanottuna Scikit-learn sisältää koko joukon algoritmeja ja menetelmiä ulottuvuuden pienentämiseksi, mallin valinnaksi, ominaisuuksien poimimiseksi ja normalisoimiseksi, vaikkakin sillä ei ole minkäänlaista ohjattua työnkulkua näiden toteuttamiseksi kuin hyvä esimerkkikokoelma ja hyvä dokumentaatio.
Scikit-learnin asentaminen ja suorittaminen
Asennukseni Scikit-Learn-ohjelmistolla on voinut olla kaikkien aikojen helpoin koneoppimisen puitteiden asennus. Koska kaikki ennakkoedellytykset oli jo asennettu ja riittävän ajan tasalla (Python, Numpy ja Scipy), se vaati yhden komennon:
$ sudo pip install -U scikit-learn
OK, se kesti kaksi komentoa, koska unohdin ensimmäisen kerran sudo.
Se sai minut Scikit-learn 0.18.1. Hyvän mittasuhteen vuoksi tarkistin myös GitHub-arkiston, asennin nenätestauskehyksen ja rakensin Scikit-learn-lähdekehityksen version, joka oli yhtä helppoa kuin vaihtaa arkiston juureksi ja kirjoittaa tehdä. Pythonin kääntäminen, kaikkien C-tiedostojen luominen ja kokoaminen, kokoonpanon linkittäminen ja kaikkien testien suorittaminen kesti jonkin aikaa, mutta se ei vaadi mitään toimenpiteitä.
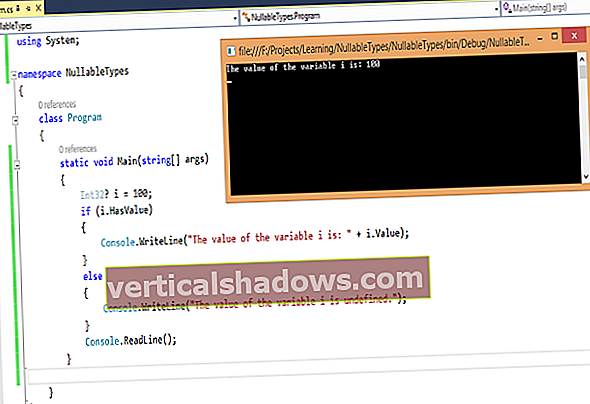
Ensimmäisen Scikit-learn-esimerkkini suorittaminen oli myös erittäin helppoa. Napsautin yleisten esimerkkien sivulta esimerkkiä ristivalidoitujen ennusteiden piirtämiseksi, luin muistikirjan läpi, ladasin Python-lähdekoodin ja Jupyter-muistikirjan ja suoritin ne. Python-lähde halaili muutaman sekunnin ajan, loi varoitusviestejä ja avasi kaavion. Jupyter-muistikirja teki olennaisesti saman, kun käytin sitä interaktiivisesti, kuten alla olevasta kuvasta näet.

Scikit-learn ansaitsee korkeimmat pisteet kehityksen helppoudesta kaikkien testaamieni koneoppimiskehysten joukossa, lähinnä siksi, että algoritmit toimivat mainostettuna ja dokumentoituna, API: t ovat johdonmukaisia ja hyvin suunniteltuja, ja niiden välillä on vähän "impedanssin epäsuhteita" Tietorakenteet. On ilo työskennellä sellaisen kirjaston kanssa, jossa ominaisuudet on perusteellisesti täydennetty ja vikoja perusteellisesti poistettu.
Oppiminen Scikit-oppia
Scikit-learn-dokumentaatio on hyvä, ja esimerkkejä on paljon - yhteensä noin 200. Useimmat esimerkit sisältävät ainakin yhden käyrän, joka on tuotettu analysoiduista tiedoista käyttäen Matplotlibiä. Nämä kaikki myötävaikuttavat kirjaston kehittämisen ja oppimisen helppouteen.
On yksi pitkä opetusohjelma "Tilastollisen oppimisen opetus tieteelliseen tietojenkäsittelyyn", jossa on viisi osiota ja liite avun löytämisestä. Opetusohjelma on melko hyvä, sekä kattamaan peruskäsitteet että esittämällä esimerkkejä todellisten tietojen, koodin ja kaavioiden avulla. Siinä kutsutaan myös tekstiin liittyviä esimerkkejä - esimerkiksi neljän eri SVM-luokittelijan vertailu alla olevassa kuvassa.

Esimerkit, jotka työskentelin läpi, olivat kaikki melko selkeitä heidän verkkosivuillaan. Monissa tapauksissa, kun ladasin ja suoritin esimerkkejä, he heittivät varoituksia, joita ei näytetä verkkosivulla, mutta tuottivat aina samat tulokset. Ensimmäinen yllä oleva kuva, joka näyttää Jupyter-muistikirjani ristiin validoitujen ennusteiden piirtämistä varten, on hyvä esimerkki.
Tunnistan suurimman osan varoituksista Apple vecLib -kehyksen puutteisiin ja Python-kirjastojen kehitykseen. Jotkut näyttävät olevan varoituksia Python 2.7.10: ssä, joita ei ollut missään versiossa, jota verkkosivulle käytettiin. Alla olevassa kuvassa on tällainen varoitus; vastaava verkkosivu ei.

Koneoppimisen Python-kirjastona, tarkoituksella rajoitetusti, Scikit-learn on erittäin hyvä. Siinä on laaja valikoima vakiintuneita algoritmeja integroidulla grafiikalla. Se on suhteellisen helppo asentaa, oppia ja käyttää, ja siinä on hyviä esimerkkejä ja oppaita.
Toisaalta Scikit-learn ei kata syvää oppimista tai vahvistavaa oppimista, mikä jättää pois nykyiset kovat mutta tärkeät ongelmat, kuten tarkan kuvaluokituksen ja luotettavan reaaliaikaisen kielen jäsentämisen ja kääntämisen. Lisäksi se ei sisällä graafisia malleja tai sekvenssiennustusta, sitä ei voida käyttää muilta kieliltä kuin Pythonilta, eikä se tue PyPyä tai GPU: ta.
Tarttuvassa kynsissä suorituskyky, jonka Scikit-learn saavuttaa koneoppimiselle muulla kuin hermoverkoilla, on melko hyvä, jopa ilman PyPyn tai GPU: iden kiihtyvyyttä. Python on usein nopeampi kuin ihmiset odottavat tulkkilta, ja Cythonin käyttö C-koodin luomiseen sisäisille silmukoille eliminoi suurimman osan Scikit-Learnin pullonkauloista.
Jos olet kiinnostunut syvällisestä oppimisesta, kannattaa etsiä muualta. Siitä huolimatta on monia ongelmia - aina erilaisten havaintojen yhdistävän ennustefunktion rakentamisesta havaintojen luokitteluun rakenteen oppimiseen leimaamattomassa tietojoukossa - jotka sopivat tavalliseen vanhaan koneoppimiseen tarvitsematta kymmeniä neuronikerroksia, ja näille alueille Scikit -Opi on erittäin hyvä.
Jos olet Python-fani, Scikit-learn voi olla paras vaihtoehto tavallisten koneoppimiskirjastojen joukossa. Jos pidät Scalasta, Spark ML saattaa olla parempi valinta. Ja jos haluat suunnitella oppimisputkesi piirtämällä kaavioita ja kirjoittamalla satunnaisen katkelman Pythonista tai R: stä, Microsoft Cortana Analytics Suite - erityisesti Azure Machine Learning Studio - saattaa sopia mieltymyksiisi.
---
Kustannus: Ilmainen avoimen lähdekoodin.Alusta: Vaatii Pythonin, NumPyn, SciPyn ja Matplotlibin. Julkaisut ovat saatavilla MacOS-, Linux- ja Windows-käyttöjärjestelmille.
| Tuloskortti | Mallit ja algoritmit (25%) | Kehityksen helppous (25%) | Dokumentointi (20%) | Esitys (20%) | Helppo käyttöönotto (10%) | Kokonaispistemäärä (100%) |
|---|---|---|---|---|---|---|
| Scikit-oppia 0.18.1 | 9 | 9 | 9 | 8 | 9 | 8.8 |